|
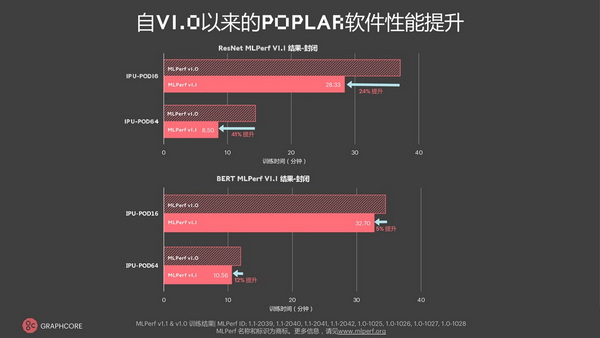
2021年12月2日,北京―― 今日,Graphcore(拟未)正式公布其参与MLPerf测试的最新结果。结果显示,与首次提交的MLPerf训练结果相比,对于ResNet-50模型,Graphcore通过软件优化,在IPU-POD16上实现了24%的性能提升,在IPU-POD64上实现了41%的性能提升;对于自然语言处理(NLP)模型BERT来说,在IPU-POD16上实现了5%的性能提升,在IPU-POD64上实现了12%的性能提升。此次MLPerf测试结果证明了Graphcore的IPU系统越来越强大、高效,软件日益成熟且更快、更易使用。
MLPerf还对比了市面上的Graphcore与NVIDIA的产品,通过在GPU占据优势的模型ResNet-50上进行测试,结果表明Graphcore的IPU-POD16在计算机视觉模型ResNet-50方面的表现优于NVIDIA的DGX
A100。在DGX A100上训练ResNet-50需要29.1分钟,而IPU-POD16仅耗时28.3分钟,这是自Graphcore首次提交以来仅通过软件实现的性能提升。其中,IPU-POD16对ResNet-50的软件驱动性能提高了24%,在IPU-POD64上对ResNet-50的软件驱动性能提升甚至更高,达到41%,对于Graphcore具有里程碑式的意义。

Graphcore最近发布的IPU-POD128和IPU-POD256横向扩展系统也得出了结果,与上一轮MLPerf训练相比,Graphcore的IPU-POD16的BERT性能提高了5%,IPU-POD64的BERT性能提高了12%。
-
对于Graphcore较大的旗舰系统,在IPU-POD128上训练ResNet-50的时间为5.67分钟,在IPU-POD256上为3.79分钟。
- 对于自然语言处理(NLP)模型BERT,Graphcore在开放和封闭类别分别提交了IPU-POD16、IPU-POD64和IPU-POD128的结果,在新的IPU-POD128上的训练时间为5.78分钟。
MLPerf的封闭分区严格要求提交者使用完全相同的模型实施和优化器方法,其中包括定义超参数状态和训练时期。开放分区旨在通过在模型实施中提供更大的灵活性来促进创新,同时确保达到与封闭分区完全相同的模型准确性和质量。通过在开放分区展示BERT训练的结果,Graphcore能够让客户了解产品在实际运行中的性能,从而让他们更倾向于使用此类优化。
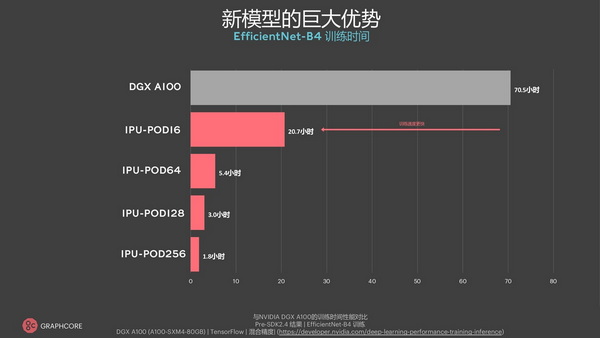
新模型在大规模系统上的巨大优势
MLPerf及其组织机构MLCommons作为第三方验证机构,在帮助客户独立评估人工智能计算系统的能力和不同公司提供的软件栈的成熟度方面发挥着重要作用。当然,客户继续在生产中使用ResNet和BERT等模型的同时,也在探索创新的新模型,并期待Graphcore更大的旗舰系统实现大规模机器智能。例如,在Graphcore的旗舰产品IPU-POD256上,创新的计算机视觉EfficientNet-B4仅用1.8小时便可完成训练,尽管这并非Graphcore本次向MLPerf提交的内容,但在实际应用中的确有更强的性能优势。
此外,在绝对吞吐量性能以及扩展到更大的IPU-POD系统方面,Graphcore在MLPerf之外的一系列模型中也得到了一系列令人印象深刻的结果,包括用于自然语言处理的GPT类模型和用于计算机视觉的ViT(Transformer视觉模型)。
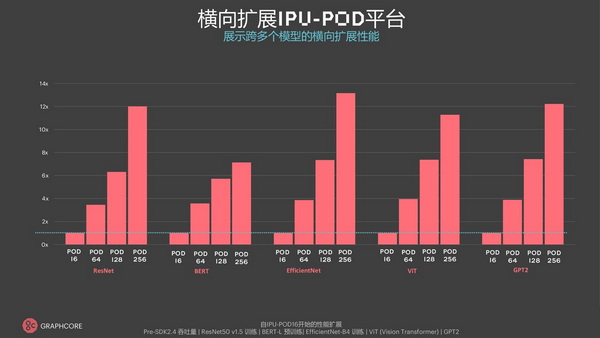
通过设计实现大规模高效
在本轮或任何一轮MLPerf原始数据中,每个制造商系统相关的主机处理器数量都十分惊人,一些参与者甚至指定要求每两个人工智能处理器配有一个CPU。而Graphcore的主机处理器与IPU的比率始终是最低的。与其他产品不同,IPU仅使用主机服务器进行数据移动,无需主机服务器在运行时分派代码。因此,IPU系统需要的主机服务器更少,从而实现了更灵活、更高效的横向扩展系统。
对于BERT-Large这一类自然语言处理模型,IPU-POD64只需要一个双CPU的主机服务器。ResNet-50需要更多的主机处理器来支持图像预处理,因此Graphcore为每个IPU-POD64指定了四个双核服务器。1比8的比例仍然低于其他所有MLPerf参与者。事实上,在本轮MLPerf
1.1训练中,Graphcore为BERT提供了最快的单服务器训练时间结果,为10.6分钟。
Graphcore大中华区总裁兼全球首席营收官卢涛表示:“自2021年初首次提交MLPerf测试以来,Graphcore取得了巨大进步,这与Graphcore不懈创新的企业精神是分不开的。无论是设计系统、选择架构之初,还是至少每三个月推出一次重大软件更新,都是Graphcore创新精神的体现。同时,Graphcore不懈创新的热情也感染和吸引了众多软硬件合作伙伴――从Hugging
Face和PyTorch Lightning到VMware和Docker Hub,它们都积极支持Graphcore不断创新,以助力AI开发者在易于使用的系统上获得绝佳的人工智能计算性能。” | 